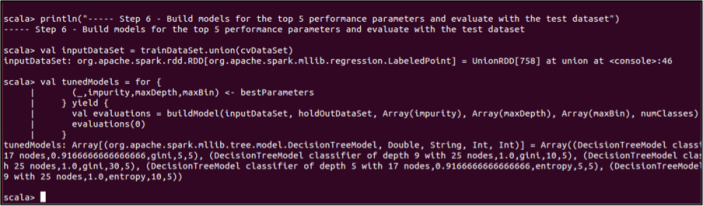
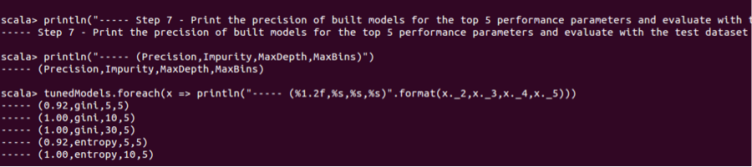
Reading time: 20 minutes

In this post, I’d like to share some ideas, concepts, thoughts and a product I’ve been developing for several months in order to get some feedbacks, comments and thoughts from you.
I’ve been spending a lot time on thinking how to combine new technology trends (in particular cognitive computing, data science, big data, stream-based processing) and math in order to help businesses increase their sales. This is the holy grail of every business.
So, if my proposal resonates after sharing, please feel free to let me know your thoughts.
Every business should receive feedback from the customers in order to improve the processes and products and make the customers happier. Happy customers lead to more sales (with new sales, cross-selling and up-selling) and referrals to other potential customers.
At the end of the day, if you know what’s really important to your customers and you measure their experience (quality, service, environment, etc); then you can increase the customer’s engagement and finally increase your own sales.
A rule of thumb could be: “better feedbacks implies adapting your business and products that implies increasing customer’s loyalty that finally implies more sales“. One step further is getting and measuring feedbacks in real-time, so you can solve issues while the customer is still interacting with your business.
For example, hospitality and lodging industry is the one that lives and dies by the perception of customers and its own reputation by further comments. It’s well know that increasing the guests loyalty implies increasing the referrals and the ranking in social networks such as TripAdvisor and impacting positively on the revenue. So, it’s very important to hear and know what guests think about your business regardless if you’re the CEO, the revenue manager, the marketing manager or just the front-desk man.
So, we have key questions such as:
- How do I reach my customers in an easy and cost-effective way? Today, there are a lot of channels to reach the customers. Some are cheap (such as my web site, email, twitter, etc) while others are very expensive (TV ads, Super Bowl ads, etc).
- How do I reach my customer almost real-time in order to act pro-actively? I don’t want to wait several days for a phone interview. I’d like to know what’s thinking now or at least in the short-term.
- How do I gather and measure objectively what the customer thinks about? I need to use math and cognitive computing in order to measure objectively the customer’s experience by filtering out some subjectivity. As well, I need to make comparable different measurements/experiences in order to get correct insights.
- How do I influence my customers to send back feedbacks? For most of the customers, filling in old-fashion paper comment cards is not so good; so we need to design sexy and easy-to-understand comment cards to motivate the customers to fill it in.
The proposed solution is an information technology (for reducing cost and time to reach the customer) that displays an intuitive and sexy digital comment card (reducing paper costs and being eco-friendly) that helps to gather surveys easily and computes automatically the captured data (reducing computing time to get a result) and finally provides insights about your business for increasing the sales.
First of all, the product enables defining a questionnaire (a list of questions) for the digital comment card. When the digital comment card is sent to the customer, then five questions are randomly selected from the questionnaire and displayed to the customer in a sexy and easy-to-understand way as shown in the figure 01.

Figure 01
Then the customer select according to his/her experience. The product internally uses a math algorithm to convert the survey response into an actionable and objective index.
The idea is to assign a weight to each face and multiply by its distribution, so mathematically the index = sum(face_dist*face_weight).
Let’s suppose that we assign the weights as: bad_face_weight=0, neutral_face_weight =50 and happy_face_weight =100 and see some scenarios:
- If every response is bad, then we have the distribution bad_face_dist=100%, neutral_face_weight =0%, happy_face_weight =0% and the index is equal to 0*1 + 50*0 + 100*0 = 0 (the lowest index value)
- If every response is good, then we have the distribution bad_face_dist=0%, neutral_face_weight =0%, happy_face_weight =100% and the index is equal to 0*0 + 50*0 + 100*1 = 100 (the highest index value)
- If every response is neutral, then we have the distribution bad_face_dist=0%, neutral_face_weight =100%, happy_face_weight =0% and the index is equal to 0*0 + 50*1 + 100*0 = 50 (a medium index value)
- In the real world, we have a different distribution and index values between 0 and 100. Close to the 0 index is bad, close to the 100 index is good and around the 50 index is neutral
A key idea is to present a dashboard showing the number of responses related to the digital comment cards and the underlying index calculation. As well as, the product shows the calculated index for each question in the questionnaire. This is important to take actions correctly given the feedback per question and per whole comment card. You can see an example of dashboard in the figure 02.
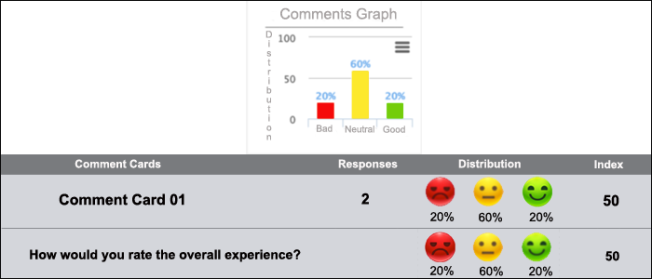
Figure 02
It’s remarkable to say that the digital comment card may be accessed using different methods:
- A link embedded in an email, newsletter, Twitter message, Facebook post, etc
- Any device such as laptop, desktop, tablet, smartphone because it’s designed to be responsive (adaptable to any display device). By this method, you can locate a tablet in the front-desk, so the customer can respond the surveys while being in your business
- A QR code posted in your billboard, printed in a paper/newspaper/magazine or just send by any digital method
Finally, the product uses cognitive computing to discover insights from the customer comments. The product uses particular the technique named sentiment analysis part of the natural language processing discipline. It consists in analyzing a human-written text/comment and gives as a result the polarity of the text: positive (good for your business), negative (bad for your business) and neutral (neither good or bad) and set of concepts related to the comment.
Let’s see a comment as shown in the figure 03.

Figure 03
We can discover several things in this comment as shown in the figure 04 such as the most important words related to the comment.
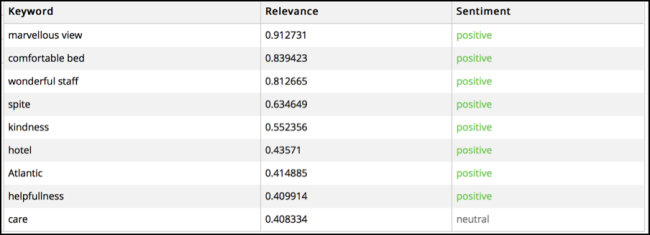
Figure 04
And the comment sentiment is shown in the figure 05.

Figure 05
The product enables to configure an email address for the case when we receive a negative comment in order to send an instant alert and act as fast as possible to solve any problem and improve the customer’s satisfaction.
I’m also thinking to include in the product the capability to discover customer segments using as an input the comments. I think to integrate the product with IBM Watson Personality Insight technology that extracts and analyzes a spectrum of personality attributes to discover the people personality. It’s based on the IBM supercomputer that famously beats humans at Jeopardy!.
Well, after sharing the key concepts and ideas of a product I’m developing, I’d like to hear from you if the problem/solution resonates to you, and if you’d like to participate in the beta testing phase.
You can reach at me: hello@nubisera.com and feel free to let me know your thoughts.
Juan Carlos Olamendy
CEO and Founder Nubisera